

My dearest, at the end of this post we'll listen to a voice, as usual, but before that we're doing a new exercise: to observe a voice. Our aim is to draw some conclusion from our observation of vowels and consonants.
Let’s start by hearing a few seconds of spoken speech:
The lower image shows the signal recorded by the microphone (you can enlarge all the images by clicking on them); we can see how the amplitude of the speech (vertical axis) evolves with the time (horizontal axis). The amplitude of the voice is directly related to its volume: a larger amplitude corresponds to a louder volume. In this case, there aren't significative variations in volume; the speaker doesn't shout or whisper, so the variations we see in this image are mostly due to the articulation of the phonemes. In this representation, called oscillogram or sonogram, we see a series of "packages" which correspond to syllables (or two syllables, sometimes); The areas with more amplitude within each "package" are the vowels. "Packages" are separated by silences, which may be pauses, breaths or plosive phonemes (corresponding to a 'p' or a 't', for example).
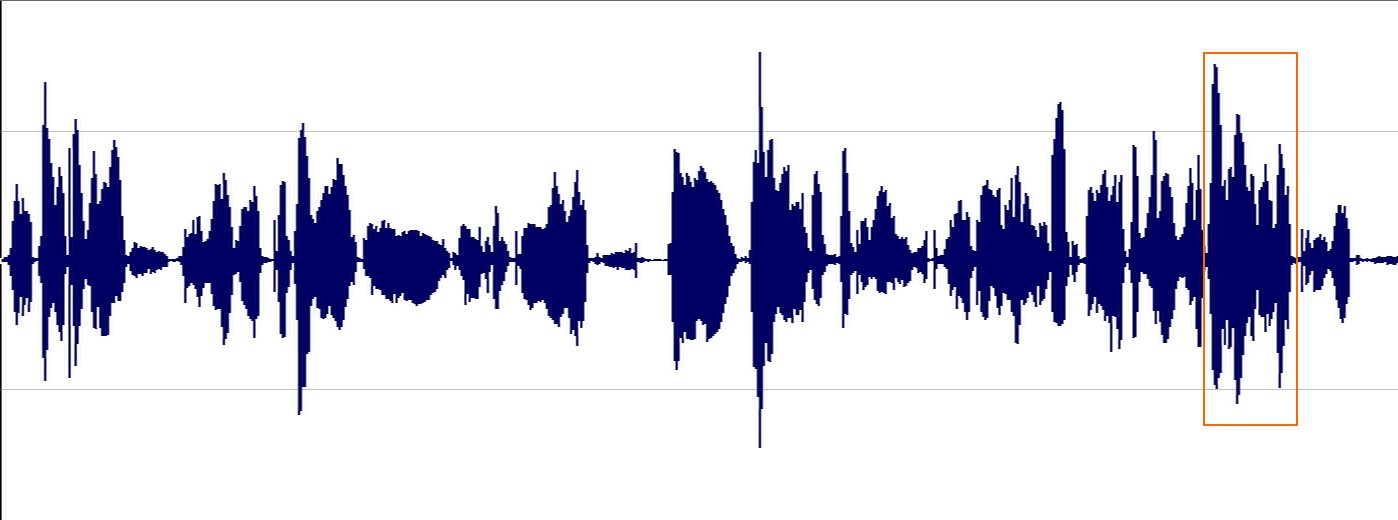
The speech structure can be seen in more detail by zooming the marked area. We distinguish the voiced phonemes, those that involve the vocal cords vibrating (all vowels and some consonants) by their regular pattern. At the end of this fragment, there's a very different phoneme (for instance, a 'sh'), the structure is no longer regular: it is a voiceless phoneme, the vocal cords don't vibrate when we pronounce it.
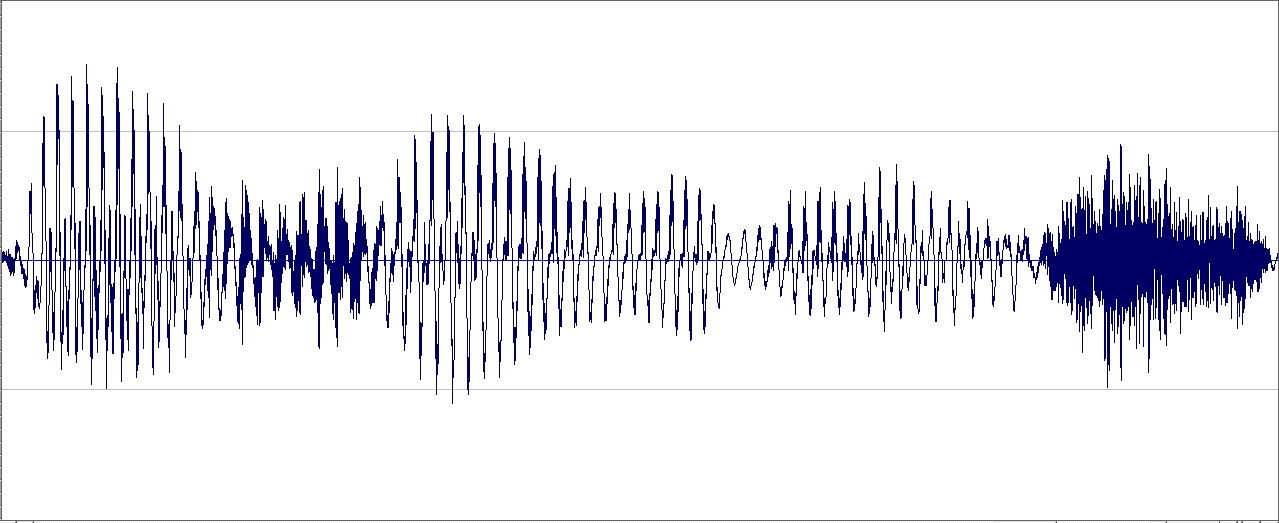
Using the sonogram, we verify something we’ve already known from experience: that we generate the highest volume when we pronounce vowels. We shout 'aaaaaaah', not 'ssst'.
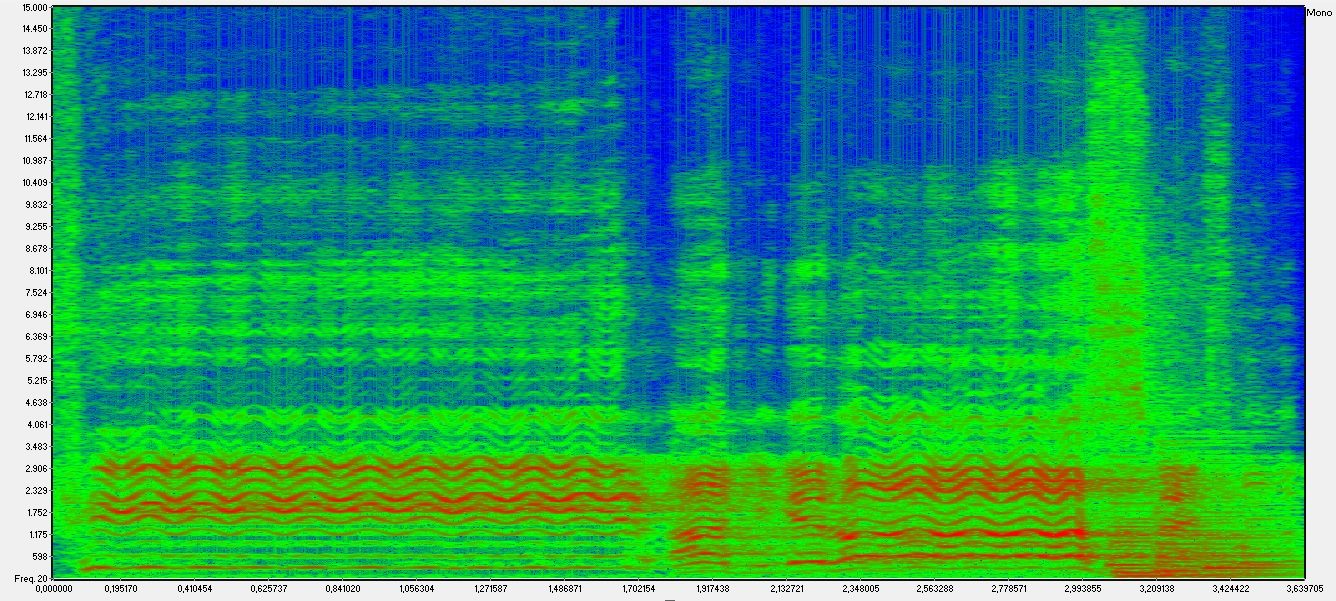
Another graphical representation, the spectrogram, will also provide information about frequency; remember that we associate notes with frequencies. The spectrogram is really useful because speech is the sum of many frequencies with different energies. I’ll spare you mathematical and technical explanations; that's the spectrogram of the same speech fragment:
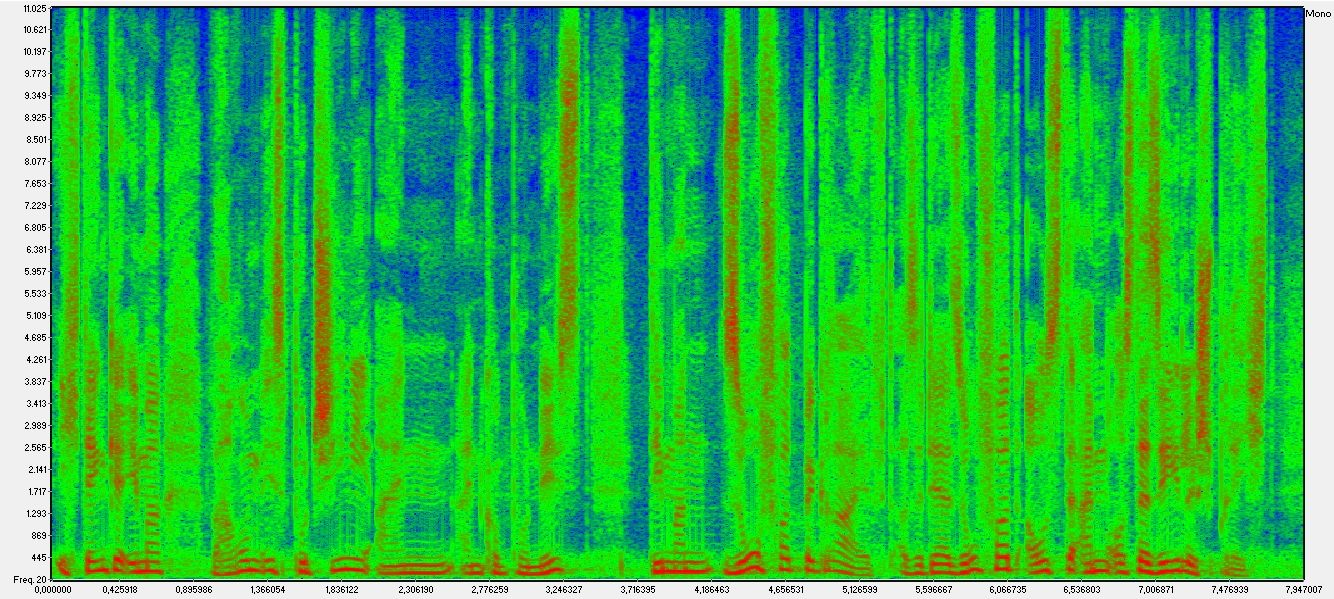
The horizontal axis still represents time, but now the vertical axis indicates the frequency. Colours show the energy that the speech has for each frequency at a given time; The highest intensity corresponds to red and the lowest, to blue; intermediate levels are green.
As shown, the highest intensities are concentrated on the lowest frequencies. Also, we can easily identify the voiced phonemes, mostly vowels, for their regular pattern: they correspond to the zones with parallel lines. The lowest line tells us which the frequency that characterizes this voice is, known as pitch; That's how our ear distinguishes the voice of a man, woman or child. The parallel lines represent the harmonics, thanks to harmonics we recognize someone by their voice. We can also distinguish voiceless phonemes in the spectrogram, as in the sonogram, by their non-regular pattern; Notice their high energy at higher frequencies (that's why we shush; 'Shh!' Is more effective than 'mmm')
Let’s focus now on the sung speech; in this fragment, we don’t hear the piano until the last syllable.

Now the sonogram does not have the usual form of the spoken speech because the voice follows the score: the first syllable is much longer (a semibreve) than the following three (quavers) and the fifth one is longer, but half of the first one (a minim).
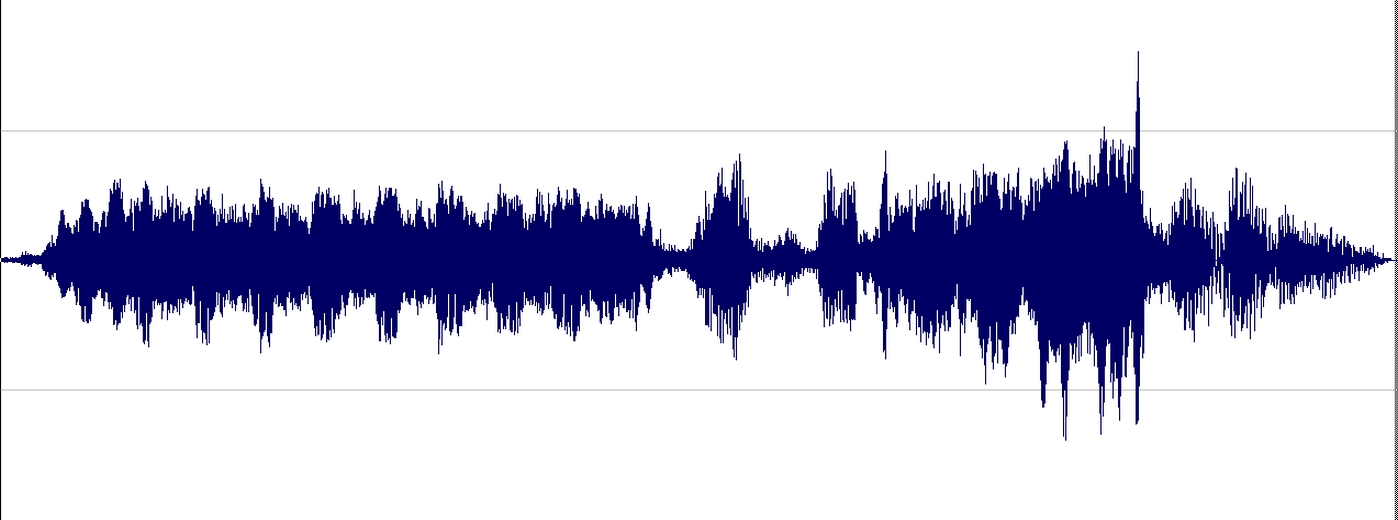
This is the sung speech spectrogram. The highest energy still concentrates in the vowels, but a clear change catches our attention: the red lines moved to higher frequencies; In fact, they moved towards the range where our ear is more sensitive. That's to say, as many of you already know, singers 'move' their voices to those frequencies which can be better heard. Maybe you might wonder about the oscillation in the parallel lines: that's the vibrato.
There's much more to be said about speech according to sonogram and spectrogram, but I think the key point has already been made: both, in spoken and sung voice, energy concentrates in vowels.
Energy concentrates in the vowels, yes, but... _nf_rm_t__n _s _n th_ c_ns_n_nts. We also knew this, didn't we? Information is in the consonants; I would say that Catalan children aren't the only ones who play to talk or sing by using just a vowel... and they easily understand each other. In a rough way, we could state that vowels are the vehicle that carries the information.
The aim of opera singers is to be heard over the orchestra (yes, one more simplification in this article). Therefore, their priority is vowels, to place them so as their voice is heard throughout the whole concert hall. And what about consonants? Well, they are sacrificed to a higher good, if necessary. Admirers of one of the 20th century greatest sopranos recognize without difficulty they couldn’t understand a single word of her singing; but they would add: who cares? Singers are even allowed to create new vowels if that would do their singing good, as one of last century essential tenors used to do; again, his admirers would say: who cares?
Instead, the aim of a song singer accompanied by a piano is not to be heard, but to be understood. He must pronounce the consonants carefully; otherwise, we can't understand them, and when we don't understand the singer, we have a problem. Good song singers have a precise diction that makes them be clearly understood, and this is one of the best things that a listener can enjoy in a recital. Because, in addition, this singer will know how to use consonants with expressive criteria; For example, I remember a teacher in a masterclass giving some advice to someone who sang a song from Winterreise. The singer should have taken advantage of the 'k' of 'kalt' to reinforce the feeling of cold, and the difference between doing so or not doing so was significant.
Now, let's imagine that a good opera singer comes occasionally to sing song. It is not that unusual that he or she is still in his or her mental framework and forgets about a small detail: consonants. And as well as a good diction makes us happy, not understanding a song leaves us cold. Or worse, we feel awkward. You may be thinking that it depends on whether we understand the language or not, but that is not a decisive factor. That's to say, not understanding a song in our own language is frustrating, but even when we listen to a language we don't know at all, we soon realize that something is going wrong; consciously or unconsciously, we realize that the song is not "complete", and it's not complete because we don't hear the consonants. That's why we are talking about vocals and consonants today. That’s something I’ve already discussed with some friends after a song recital and I promised I would discuss here...
If you have reached this point, you deserve a good reward. Jonas Kaufmann lent us his voice (spoken and sung) to make our experiments (you can listen to the complete Ich liebe dich by Richard Strauss, from which I borrowed the first measures, here). Now, I suggest you listen to him singing one of the Three Petrarch Sonnets by Liszt, Benedetto sia'l giorno, accompanied as usual by Helmut Deutsch. Enjoy his vowels and his consonants!
Benedetto sia ‘l giorno, e ‘l mese, e l’anno,
E la stagione, e ’l tempo, e l’ora, e ‘l punto,
E ‘l bel paese e ‘l loco, ov’io fui giunto
Da due begli occhi che legato m’hanno;
E benedetto il primo dolce affanno
Ch’i ebbi ad esser con Amor congiunto,
E l’arco e le saette ond’i’ fui punto,
E le piaghe, ch’infino al cor mi vanno.
Benedetti le voci tante,ch’io
Chiamando il nome di Laura ho sparte,
E i sospiri e le lagrime e ‘l desio.
E benedette sian tutte le carte
Ov’’io fama le acquisto,e il pensier mio,
Ch’è sol di lei, si ch’altra non v’ha parte.










Comments powered by CComment